重複コンテンツとは?SEOに及ぼす影響や対策方法など詳しく解説
2023年8月16日
東証スタンダード上場企業のジオコードが運営!
SEOがまるっと解るWebマガジン
 LLMO対策とは?AI検索時代に成果を出すための実装方法を徹底解説
LLMO対策とは?AI検索時代に成果を出すための実装方法を徹底解説

【監修】株式会社ジオコード SEO事業 責任者
栗原 勇一
目次
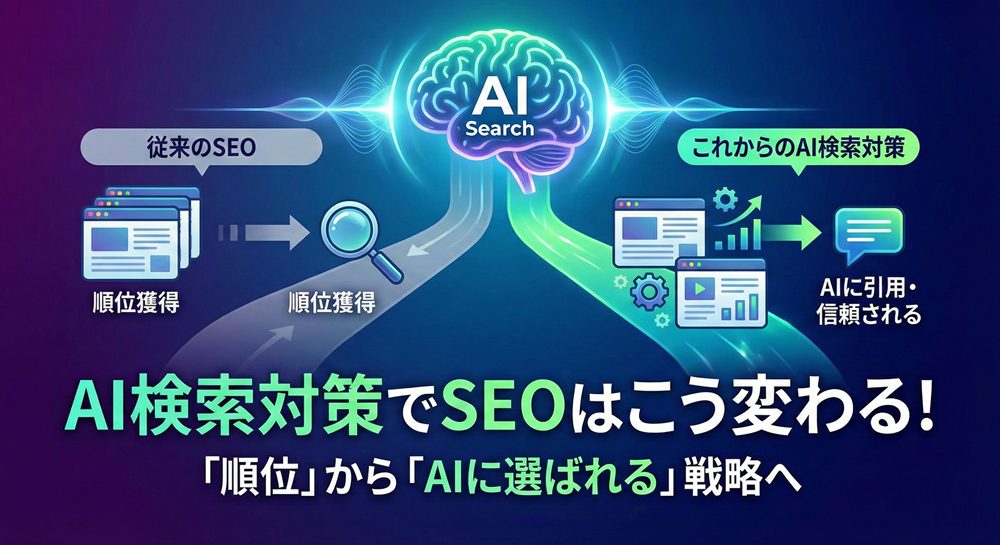
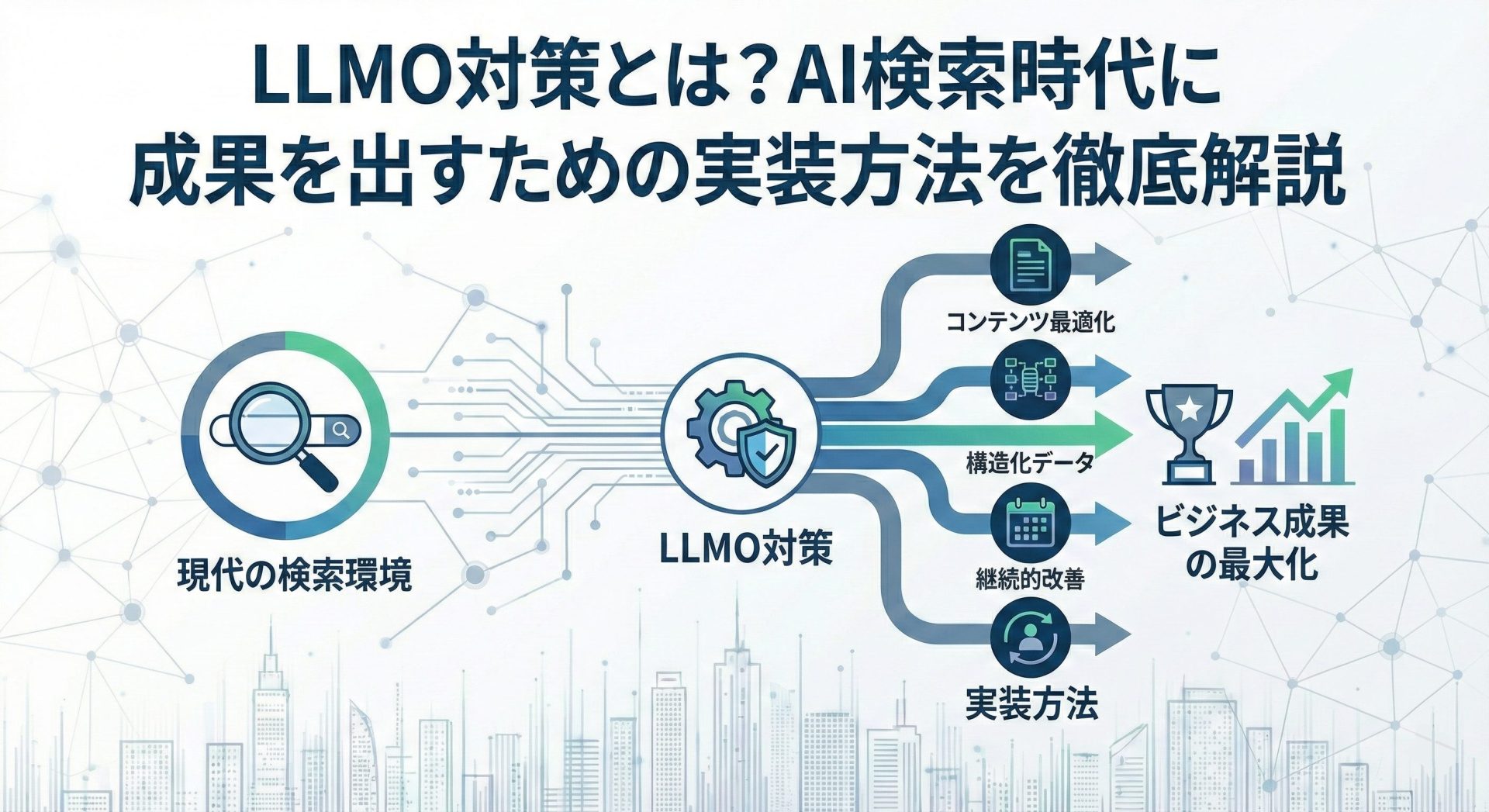
LLMO対策とは、大規模言語モデルが情報を読み取り、回答を生成する環境を前提に、情報の意味や構造を最適化する取り組みです。
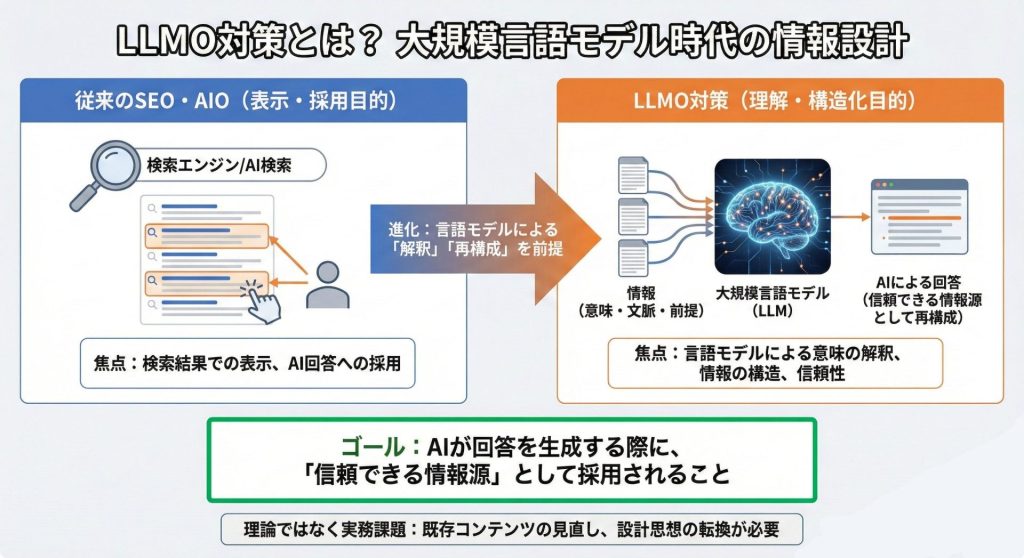
従来のSEOが主に検索エンジンでの評価向上を目的としてきたのに対し、LLMOという考え方は、言語モデルに意味が正しく伝わる構造を意識するアプローチとして語られることがあります。
AIが検索結果やチャット形式で回答を提示する機会が増えたことで、情報は単に表示されるだけでなく、再構成される対象になりました。
この変化が、LLMO対策の必要性を高めています。
LLMO対策はSEOやAIOと混同されがちですが、焦点が異なります。
SEOは検索エンジンに評価されること、AIOはAI検索における表示や採用を意識する考え方です。
LLMOはさらに一歩踏み込み、言語モデルが文章の意味をどう解釈するかに焦点を当てます。
文章の前提や文脈、一貫性がより重要になり、表面的な最適化では通用しません。
LLMO対策の最終的なゴールは、AIが回答を生成する際に、信頼できる情報源として採用されることです。
単にキーワードを含めるだけではなく、意味が安定し、誤解を生みにくい構造を持つコンテンツであることが求められます。
LLMO対策は概念論にとどまらず、実装レベルで考える必要があります。
どのように記事を設計し、どのように改善していくかが重要になります。
LLMOは新しい言葉として語られることが多い一方で、「具体的に何をすればよいのか」が曖昧になりがちです。
しかし実際には、既存コンテンツの見直しや設計思想の転換によって、十分に実装可能な取り組みです。
LLMO対策は、AI時代に情報を届け続けるための実務課題として捉える必要があります。

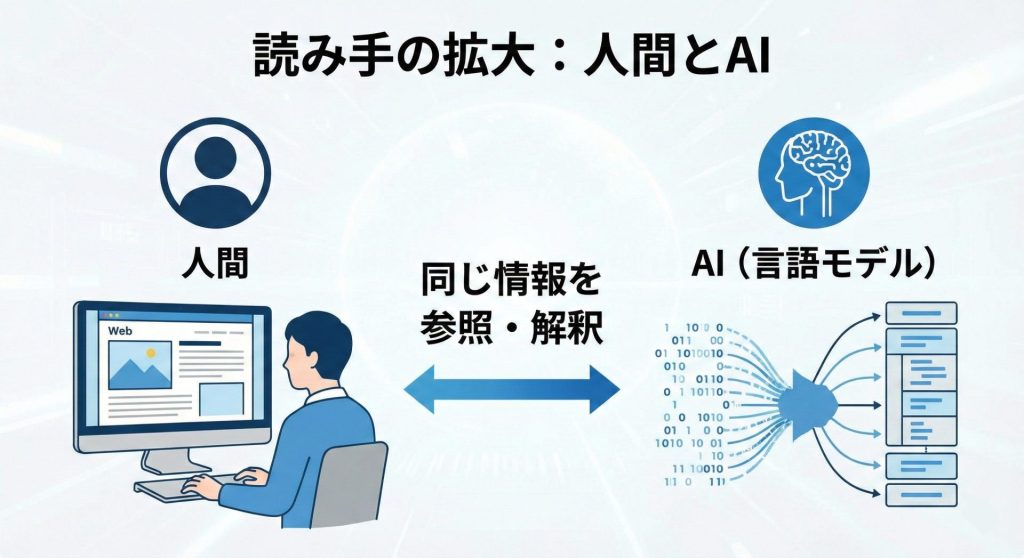
LLMO対策が必要とされる最大の理由は、コンテンツの読み手が人間だけではなくなったことです。
検索エンジンだけでなく、大規模言語モデルが情報を読み取り、回答として再構成する場面が増えています。
この環境では、文章は「読まれる」だけでなく、「解釈され、再利用される」対象になります。
言語モデルが正しく解釈しにくい情報は、回答に反映されにくい可能性があります。
従来のSEOでは、構造化やキーワード設計によって一定の成果を上げられる場面もありました。
しかし言語モデルは、文章全体の意味や前後関係を重視します。
そのため、部分的に整ったコンテンツよりも、全体として論理が一貫している情報が評価されやすくなります。
LLMO対策は、文章単位ではなく「意味単位」での最適化が求められます。
言語モデルが生成する回答は、ユーザーの理解や判断に影響を与える場面が増えています。
特に、比較や判断を伴うテーマでは、その影響力は大きくなります。
このとき、構造が整理されていない情報は、比較文脈の中で扱われにくくなる可能性があります。
言語モデルに採用されるかどうかが、ブランドやサービスの認知に直結する時代になっています。
LLMO対策はまだ広く浸透しているとは言えません。
しかし、AI検索や生成AIの活用が進むほど、言語モデルに理解される情報設計の重要性は高まります。
LLMO対策は、早期に取り組むことで将来的な情報設計の基盤づくりにつながる可能性があります。
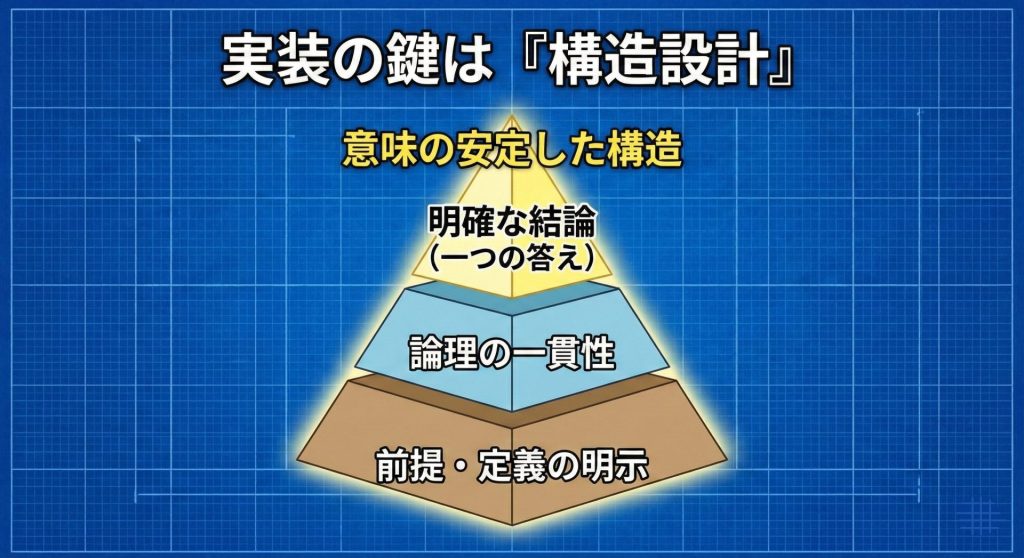
LLMO対策の実装は、記事を書き終えてから始めるものではありません。
設計段階から、言語モデルがどのように文章を解釈するかを意識する必要があります。
まず重要なのは、「この記事は何に答えるのか」を明確に定義することです。
テーマが曖昧なまま書き始めると、途中で論点がぶれ、意味が不安定になります。
LLMO対策では、記事全体を一つの答えとして設計し、その答えを支える説明を積み重ねていく構造が求められます。
言語モデルは文脈を推測する能力を持っていますが、前提が明示されている情報の方がより安定して解釈されやすい傾向があります。
そのため、専門的なテーマであっても、必要な前提や定義は文章の中で示す必要があります。
「何についての話なのか」「どの範囲に当てはまるのか」「最終的にどんな結論なのか」。
これらが自然な流れで示されていると、言語モデルは情報を安定して解釈できます。
前提が十分に示されていない文章は、解釈が揺れやすく、再構成の際に扱いづらくなる可能性があります。
LLMO対策の改善は、単語やフレーズを置き換える作業ではありません。
記事全体の構造を見直し、論理の流れが途切れていないかを確認することが重要です。
見出しと本文の整合性、段落ごとの役割、結論への導線。
これらが整理されていれば、言語モデルは情報を要約しやすくなります。
部分的な修正ではなく、構造全体を調整する視点が必要です。
言語モデルの挙動や検索環境は、今後も変化していきます。
そのため、一度最適化したコンテンツも、定期的に見直す必要があります。
情報の更新だけでなく、論理の整理や説明の明確化も含めて改善を続けることで、LLMO対策は機能し続けます。
実装とは、一度きりの施策ではなく、継続的な設計改善のプロセスです。
LLMO対策は、実装したかどうかではなく、どのように検証しているかで成果が分かれます。
理論として理解するだけでは不十分で、AI環境の中で実際にどのように扱われているかを確認する必要があります。
まず確認すべきなのは、想定クエリでのAI回答内の扱われ方です。
対象テーマで生成AIに質問し、自社の情報がどのような文脈で言及されているかを確認します。名前が出るかどうかだけではなく、どの強みが認識されているのか、想定とズレがないかを確認することが重要です。
次に、結論抽出テストを行います。
記事の冒頭部分を提示し、「この文章の結論は何か」と問いかけます。意図した結論と異なる要約が返る場合、構造に曖昧さがある可能性があります。結論が明確に抽出される構造は、AIに再利用されやすい傾向があります。
さらに、比較文脈での露出も確認します。
「〇〇と△△の違いは何か」「〇〇に向いている企業はどこか」といった質問を投げ、自社がどのポジションで語られるかを確認します。ポジショニングが曖昧な場合、意図しない立ち位置で整理されることがあります。
これらの検証を通じて、構造上の弱点が可視化されます。
LLMO対策は、実装よりも検証と改善のサイクルにこそ本質があります。
LLMO対策は「整える」だけでは不十分です。
競合に勝つには、構造そのものを一段深く設計する必要があります。
1.テーマ特化型の情報蓄積が重要です。
単発の記事ではなく、特定テーマに対して継続的に情報発信を行うことで、言語モデルに専門領域として認識されやすくなります。断片的な網羅よりも、一貫した深掘りが優位性を生みます。
2.比較軸を自ら提示することです。
AIは比較を好みます。価格、対象企業規模、導入難易度、得意領域など、どの軸で整理されるべきサービスなのかを文章内で明示することで、比較回答に組み込まれやすくなります。
3.結論先出し型のアーキテクチャ(全体の設計構造)です。
結論が明確で、その理由が段階的に展開される構造は、再構成時に意味が安定します。AIは要約前提で動くため、結論が後半に埋もれる構造は不利になります。
競合が概念説明にとどまっている場合、このレベルの構造設計まで踏み込むことで差が生まれます。
LLMO対策とは、意味の整合性を保つだけでなく、再利用される前提で設計することです。
専門性を高めるためには、限界も明示する必要があります。
言語モデルは高度な文脈理解能力を持ちますが、誤認識や要約時のニュアンス変化が起こる可能性は否定できません。また、学習データや参照情報の偏りによって、必ずしも意図どおりに評価されるとは限りません。
そのため、LLMO対策は魔法の施策ではありません。
検索エンジンへの最適化を無視することもできませんし、構造を整えたからといって即座に成果が保証されるわけでもありません。
しかし、意味が安定した構造を持つコンテンツは、長期的に再利用されやすいという傾向は見られます。
短期的な数値ではなく、中長期での情報露出を前提に取り組むことが重要です。
LLMO対策をSEOの延長として捉え、キーワードを増やせば効果が出ると考えるのは典型的な誤解です。
言語モデルは、単語の出現回数だけでなく、文章全体の意味や論理の整合性も踏まえて出力を生成する傾向があります。
不自然にキーワードを詰め込んだ文章は、意味が崩れやすく、かえって採用されにくくなります。
LLMO対策では、言葉の量よりも、意味の安定が重要になります。
言語モデルに理解されることを意識しすぎるあまり、人にとって読みづらい文章になるケースもあります。
しかし最終的に情報を判断し、行動するのは人です。
LLMO対策は、AI専用の文章を書くことではありません。
人にとって理解しやすい構造は、AIにとっても理解しやすいという前提に立つ必要があります。
LLMO対策は、すぐに順位や流入数の変化として現れる施策ではありません。
言語モデルに情報が参照され、回答に反映されるまでには時間がかかる場合もあります。
短期的な数値だけで判断すると、効果を見誤る可能性があります。
中長期で情報の質を高め続ける姿勢が求められます。
一部の文章表現を調整するだけでは、LLMO対策としては不十分です。
問題が構造にある場合、文章単位の修正では改善しません。
論理の流れ、見出しの設計、結論への導線といった全体構造を見直すことが重要です。
LLMO対策は、部分最適ではなく、全体最適を目指す取り組みです。
LLMO対策の実装で最も重要なのは、言語モデルを特別視しすぎないことです。
本質は、検索意図に対して意味が通じる答えを、安定した構造で提示できているかどうかにあります。
大規模言語モデルは、キーワードの並びではなく、文章の意味や文脈の一貫性を読み取ります。
そのため、断片的な最適化や表面的な修正では十分ではありません。
LLMO対策の実装とは、記事全体を一つの答えとして設計し、前提と定義を明確にしたうえで、結論へと自然に導く構造を整えることです。
これは新しいテクニックというよりも、情報設計の原点に立ち返る取り組みだと言えます。
ただし、AIが読み手として存在する現在では、その精度がより厳密に問われています。
LLMO対策は、一度対応して終わる施策ではありません。
情報の更新、構造の見直し、論理の整理を継続的に行うことで、言語モデルに理解され続ける状態を保つことができます。
AI検索が一般化する時代において、
重要なのは「どう目立つか」ではなく、「どうすれば誤解なく理解されるか」です。
この視点を持ってコンテンツを設計し、改善を続けられるかどうかが、
LLMO対策を実務レベルで成功させる決定的な差になります。
LLMOの重要性が高まる一方で、「実際にどう取り組めばいいのかわからない」という企業は少なくありません。
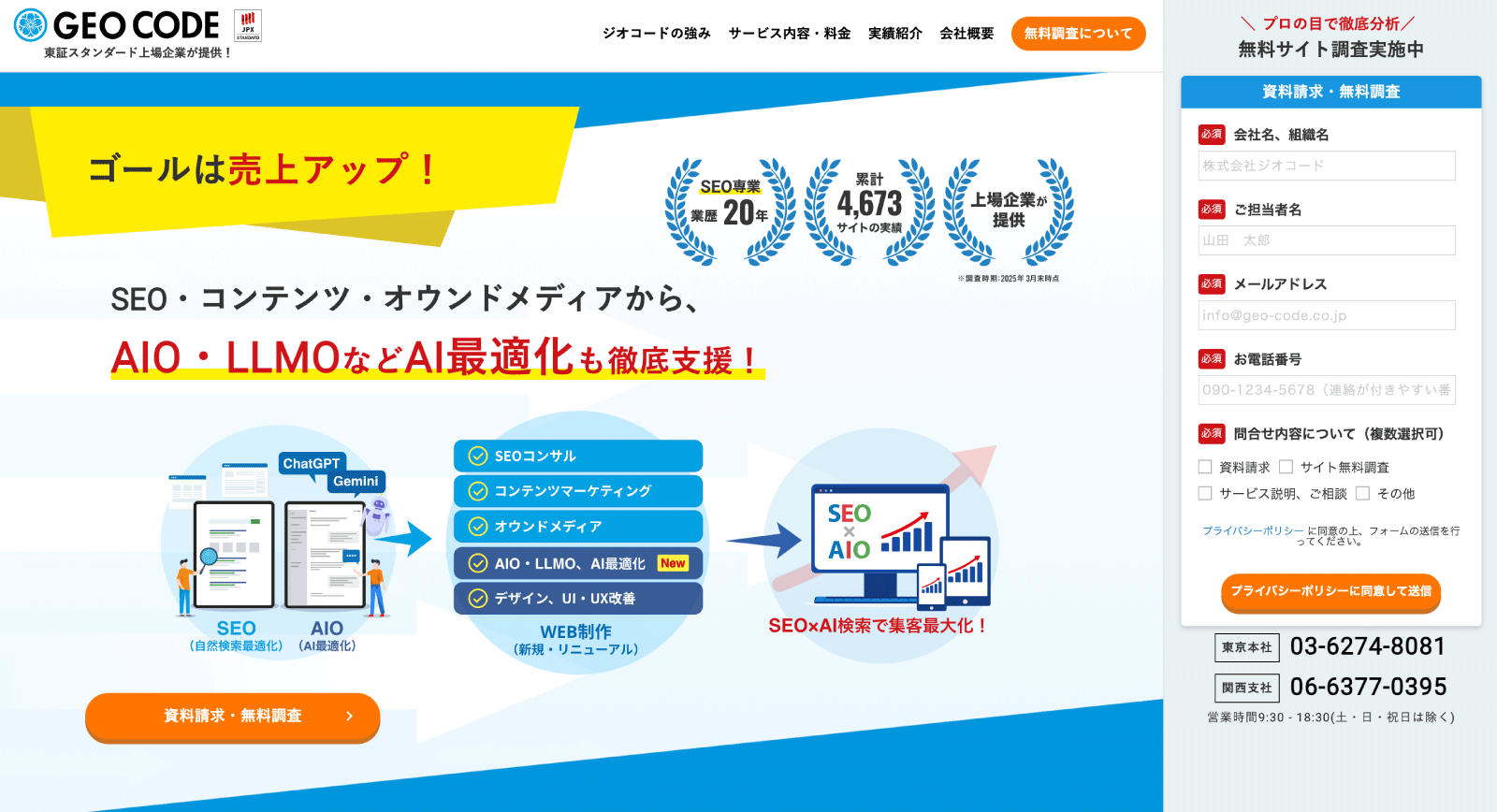
そうした中で、ジオコードは、従来のSEO支援で培ってきたノウハウを土台に、AI検索時代を前提としたオーガニックマーケティング支援を提供しています。
単なる流行対応ではなく、検索行動の変化や生成AIの仕組みを踏まえたうえで、AIに理解され、参照される情報設計を実務レベルで落とし込める点が特徴です。
ジオコードのAI最適化支援は、コンテンツを書き換えることだけを目的としていません。
検索エンジンに正しく評価されるSEOの視点と、生成AIに意味を正しく理解されるLLMOの視点を組み合わせ、情報が「評価されるところから、使われるところまで」を一貫して設計します。
そのため、検索順位の改善だけでなく、AI検索の回答文に情報が反映されることを見据えたコンテンツ設計が可能になります。
LLMOでは、キーワードや表面的な文章調整よりも、情報の意味や文脈の整理が重要になります。
ジオコードでは、クライアントの事業内容や強みを丁寧に言語化し、AIが誤解しない形で情報を構造化していきます。
定義の曖昧さや主張のブレをなくし、AIにとって「安心して使える一次情報」に整えることで、長期的に参照され続ける情報資産の構築を目指します。
ジオコードの強みは、AI最適化単体ではなく、Webサイト全体のオーガニックマーケティングを俯瞰して支援できる点にあります。
SEO、コンテンツ設計、サイト構造、ユーザー導線といった要素を組み合わせることで、AI検索に反映される前提となるサイト評価そのものを底上げします。
これにより、短期的な施策に終わらず、AI検索時代でも価値を発揮し続ける情報基盤を構築することができます。
LLMOは理解するだけでは成果につながりません。
実務に落とし込み、継続的に改善していく体制があって初めて意味を持ちます。
ジオコードは、これまでのSEO・オーガニックマーケティング支援で培った実行力を活かし、AI検索時代の情報設計を現実的な戦略として実装できるパートナーです。
LLMOやAI最適化に本気で取り組みたい企業にとって、検討価値の高い選択肢と言えるでしょう。