Webサイトのハッキングとは?概要や手口・有効な8つの対策方法を徹底解説!
2024年10月4日
東証スタンダード上場企業のジオコードが運営!
Web制作がまるっと解るWebマガジン
更新日:2026年 06月 12日


【監修】株式会社ジオコード Web制作事業 責任者
坂従 一也
サーバー障害対策は、障害が起きたあとに慌てて対応するためのものではありません。
止まりにくい構成を作ることと、止まっても早く戻せる状態を整えることの両方が重要です。
IPAは、重要インフラ分野の障害対策として、可用性管理、冗長化設計、変更管理、容量や能力の管理などの重要性を示しています。
AWS Well-Architectedの信頼性の柱では、障害からの自動復旧、復旧手順のテスト、水平スケーリング、変更の自動化などを設計原則として挙げています。
障害は起こり得る前提で構築と運用を考える必要があると案内しています。
サーバー障害というと、ハードウェア故障だけを思い浮かべることがあります。
しかし実際には、設定変更ミス、更新作業の失敗、リソース不足、ネットワーク障害、クラウド側の障害、バックアップ不備など、原因は一つではありません。
IPAの障害対策資料では、構成管理、変更管理、サービス継続・可用性管理、容量・能力管理などが、障害対策で重要な管理領域として整理されています。
このことからも、サーバー障害対策は機器交換だけでなく、運用の整え方まで含めて考える必要があります。
この記事では、サーバー障害対策の基本から、なぜ備えが必要なのか、優先して見直したい施策、進めるときに押さえたい注意点までを順に整理します。
原因を並べるだけではなく、現場で何を見直せば止まりにくくなり、止まっても戻しやすくなるのかが見える形でまとめます。
サーバー障害対策が重要なのは、普段は正常に動いていても、障害は前触れなく発生し得るからです。
AWSの信頼性設計では、利用者側のワークロードが障害から復旧できるように設計・運用・テストする考え方が重視されています。
常に障害を前提に環境構築や運用を考える必要があると案内しています。
Google Cloudも、ディザスタリカバリ(DR)計画のガイドで、障害時にどう設計し、どう復旧するかを事前に決めておくことの重要性を示しています。
見た目には安定して稼働している。
監視アラートも出ていない。
その状態でも、部品故障、構成変更、急な負荷増加、クラウド基盤の障害などで停止することがあります。
そのため、サーバー障害対策では「今動いているから大丈夫」と考えるのではなく、「いつ止まっても不思議ではない」という前提で備えることが大切です。
サーバー障害の影響は、一台の停止だけで終わらないことがあります。
Webサーバーが止まれば、問い合わせや受注の機会を失うことがあります。
認証基盤が止まれば、社内システム全体へ影響が広がることがあります。
ファイルサーバーやデータベースが停止すれば、業務の継続そのものが難しくなることもあります。
IPAは、可用性管理や冗長化設計だけでなく、変更管理や容量管理まで含めて障害対策として重要だと示しています。
これは、障害が技術的なトラブルにとどまらず、業務継続の問題として広がることを前提にしているからです。
だからこそ、サーバー障害対策はIT部門だけの話ではなく、事業継続の観点からも見直す必要があります。
サーバー障害対策で本当に重要なのは、障害をなくすことだけではありません。
障害が起きても業務への影響を小さく抑えることです。
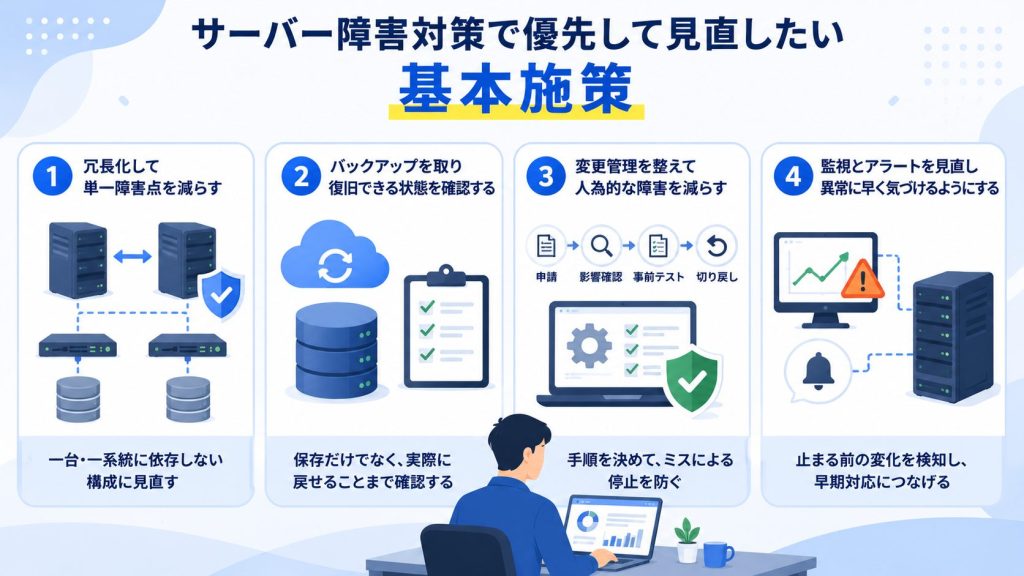
サーバー障害対策でまず見直したいのが、単一障害点をできるだけ減らすことです。
IPAは、重要インフラ分野の障害対策として、冗長化設計や可用性管理の重要性を示しています。
AWSも、障害は起こり得る前提で設計する考え方を案内しており、一台や一系統に依存しない構成が重要だとわかります。
アプリケーションサーバーが一台だけになっている。
データベースが単一構成のままになっている。
ネットワーク経路やストレージが一系統しかない。
こうした状態では、どこか一か所の障害がそのままサービス停止につながりやすくなります。
そのため、まずどこが止まると全体が止まるのかを洗い出し、冗長化できる部分から見直すことが重要です。
サーバー障害対策では、バックアップの取得も欠かせません。
ただし、取得しているだけでは十分ではありません。
Google Cloudは、災害復旧計画のガイドで、復旧手順や復旧目標を事前に整理する重要性を示しています。
このことからも、バックアップは保存の有無だけではなく、実際に戻せるかまで確認する必要があるとわかります。
データのバックアップはある。
しかし、復元手順が曖昧になっている。
設定ファイルや構成情報が残っていない。
復旧に必要な権限や担当者が決まっていない。
こうした状態では、いざ障害が起きたときに復旧が遅れやすくなります。
サーバー障害対策では、バックアップの存在より、どの順番でどこまで戻せるのかを明確にしておくことが重要です。

サーバー障害の原因は、機器故障だけではありません。
IPAは、障害分析の教訓として、変更管理の不備が問題になりやすいことを整理しています。
このことからも、構成変更や更新作業の進め方を整えることが、サーバー障害対策の大きな柱だとわかります。
本番環境へ直接変更を入れている。
事前確認なしで設定を切り替えている。
切り戻し手順を決めずに更新している。
こうした運用では、小さなミスが停止につながりやすくなります。
そのため、作業申請、影響確認、事前テスト、切り戻し手順まで含めて変更管理を整えることが重要です。
サーバー障害対策では、異常を早く見つける仕組みも欠かせません。
AWSの信頼性設計では、障害を前提にした運用と観測の重要性が示されています。
IPAも、可用性管理や能力管理の重要性を整理しており、状態を把握できることが障害影響の抑制につながると考えられます。
CPUやメモリの逼迫に気づけるか。
ディスク使用量の増加を追えているか。
プロセス停止や応答遅延を検知できるか。
通知先や一次対応者が決まっているか。
こうした点を見直しておくと、完全停止に至る前に手を打ちやすくなります。
サーバー障害対策では、止まったあとに知るのではなく、止まる前の変化を拾える状態を作ることが大切です。
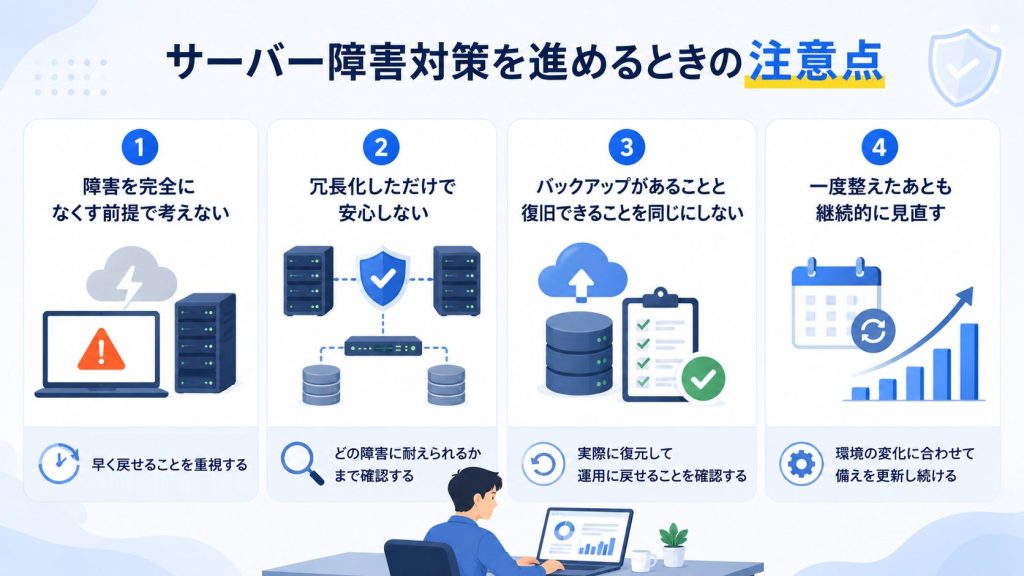
サーバー障害対策を進めるときにまず意識したいのは、障害を完全になくす前提で考えないことです。
AWSの信頼性設計では、障害は起こり得るものとして設計し、運用し、改善する考え方が示されています。
Google Cloudの障害復旧計画ガイドでも、障害発生後にどう復旧するかを事前に設計しておく必要があると整理されています。
このことからも、重要なのは「止まらないこと」だけではなく、「止まっても早く戻せること」だとわかります。
冗長化を入れている。
監視も動いている。
バックアップもある。
それでも障害が起こる可能性はあります。
だからこそ、発生確率を下げる対策と、発生後の影響を小さくする備えを分けて考える必要があります。
サーバー障害対策では、冗長化すれば十分だと考えないことも重要です。
IPAは、耐障害性を向上させ可用性を確保するために、機器やネットワークを極力冗長化する設計が重要だと示しています。
一方で、冗長化の方式や想定する障害の範囲は、リスクとコストを踏まえて設計する必要があるとしています。
このことからも、冗長化は置いて終わりではなく、どこまで守れる構成なのかを把握しておく必要があります。
待機系がある。
複数台で分散している。
クラウドでマルチAZにしている。
それでも、切り替え条件が曖昧だったり、依存先が単一だったりすると、思ったように止まりにくくはなりません。
冗長化の有無だけで判断せず、どの障害に耐えられるのかまで確認することが大切です。
サーバー障害対策では、バックアップを取っているだけで安心しないことも大切です。
Google Cloudの障害復旧計画ガイドは、DR計画を設計して実装するために、復旧目標や復旧方法を明確にする必要があると示しています。
Google Cloudでは、ディザスタリカバリを、障害発生後にITシステムやサービスを復旧できるようにするための計画と仕組みとして説明しています。
つまり、バックアップの存在だけではなく、どの時間でどこまで戻せるのかが重要です。
データのコピーはある。
しかし、設定ファイルが残っていない。
復元手順が共有されていない。
担当者しか戻し方を知らない。
こうした状態では、障害時に復旧が遅れやすくなります。
サーバー障害対策では、保存していることより、実際に復元して運用へ戻せることを確認する必要があります。
サーバー障害の原因は、機器故障だけではありません。
IPAは、障害分析の教訓として、構成管理、変更管理、可用性管理、容量や能力管理の問題が多いと整理しています。
このことからも、サーバー障害対策では、技術設定だけではなく、運用の進め方そのものが大きなテーマだとわかります。
本番環境へ直接変更を入れている。
事前確認なしで設定を切り替えている。
切り戻し手順を決めずに更新している。
このような運用では、小さなミスが大きな停止につながりやすくなります。
そのため、作業申請、影響確認、事前テスト、切り戻し手順、障害時の連絡系統まで含めて整えることが重要です。
サーバー障害対策は、一度整えたら終わりではありません。
AWSのReliability Pillarでは、信頼性は継続的な改善プロセスであり、テストしなければ信頼できる状態とは言えないと示されています。
IPAも、可用性管理や容量や能力管理を継続して行うことの重要性を示しています。
このことからも、障害対策は固定された答えではなく、環境の変化に合わせて見直すべきものだとわかります。
新しいサーバーを追加する。
クラウド構成を変更する。
監視項目を増やす。
バックアップ先を変える。
こうした変化があるたびに、想定すべき障害の形も変わります。
そのため、サーバー障害対策は導入時の設計だけでなく、運用しながら更新し続けることが欠かせません。
サーバー障害対策で大切なのは、一度整えた構成を維持することではなく、変化に合わせて備えを更新し続けることです。
サーバー障害対策は、障害が起きたあとに慌てて対応するためのものではありません。
止まりにくい構成を作ることと、止まっても早く戻せる状態を整えることの両方が重要です。
IPAは、障害対策手法として、可用性管理、冗長化設計、変更管理、容量や能力の管理などの重要性を示しています。
AWSも、信頼性設計の考え方として「Design for Failure(障害を前提とした設計)」を挙げ、障害は起こり得る前提で構築と運用を考える必要があると案内しています。
優先して見直したい施策としては、単一障害点を減らすための冗長化、バックアップだけでなく復旧できる状態の確認、変更管理の整備、監視とアラートの見直しが挙げられます。
IPAは、耐障害性を向上させるために機器やネットワークの冗長化が重要だと示しています。
Google Cloudも、障害復旧計画では復旧目標や復旧方法を事前に設計する必要があると案内しています。
このことからも、障害対策は構成の工夫だけでなく、復旧の準備や運用手順まで含めて考える必要があります。
また、サーバー障害対策を進めるときは、障害を完全になくす前提で考えないことも大切です。
冗長化しただけで安心しないこと。
バックアップがあることと復旧できることを同じにしないこと。
技術対策だけでなく変更管理や運用手順まで整えること。
こうした視点がないと、備えがあるつもりでも障害時に機能しにくくなります。
さらに、サーバー障害対策は一度整えたら終わりではありません。
新しいサーバーを追加する。
クラウド構成を変更する。
監視項目を見直す。
バックアップ先を変える。
こうした変化があるたびに、想定すべき障害の形も変わります。
そのため、障害対策は導入時の設計だけでなく、運用しながら更新し続けることが欠かせません。
サーバー障害対策で本当に重要なのは、障害をゼロにすることではありません。
障害が起きても業務停止を長引かせないことです。
どこが止まると全体へ影響するのかを把握することです。
復旧手順を曖昧にしないことです。
そして、構成や運用の変化に合わせて見直しを続けることです。
そうした積み重ねが、現実的で効果のあるサーバー障害対策につながります。